Quick idea
Google and various other Silicon Valley entities should create a Public Domain fund. Basic idea is that you submit some creative work (a song, image, etc.) and through the magic of up-down voting, the top X entries win some Y dollars. Only catch is that if you take money from the fund, your work must now be in the public domain.
Rationale
A large number of people and groups depend on there being a robust public domain (or at least things easily redistributable via Creative Commons) — from lip dubs to remixes to fan fiction to mere inspiration, a substantial amount of creative expression takes the form of a derivative work. Whenever I feel the need to Photoshop (or GIMP) something together, I often spend a lot of time on Google Image Search or Flickr looking for source material. I imagine I’m not alone. Much of the derivative work out there gets by on fair use, but there’s definitely a good chunk of it doesn’t (or hovers in some gray area).
Furthermore, obtaining licensing and permissions from the original right holders is a tremendous hassle. There’re legal documents to be signed, dollars to be transferred, and hours to be wasted while you wait for someone to respond to your e-mail. Furthermore, the market value for a lot of these mash-ups is uncertain and probably not worth any licensing fee. More often than not, I’d bet that the creators of derivative works do one of two things: (1) give up on the current project or (2) use the source material without permission.
These derivative work creators would benefit from a large body of public domain works available for use. Now I’m not saying there isn’t already stuff out there. I certainly am usually able to find what I need given enough time, but it’d definitely make things a lot easier if public domain / less restrictive licensing were the norm. A Public Domain Fund would provide an economic incentive for creators to use less restrictive licensing.
More … I really didn’t want to pay for flash card software to help with studying, so I spent a few hours cobbling together FlasCar — my ghetto flash card program. It’s a Python script that parses a data file and generates an HTML / Javascript (jQuery) page that you can use.
Click here to try out the demo.
If you’re interested, you can download the Python script and make your own Javascript-powered flash cards. The details are in the README file. If you’re running Windows, you’ll need to install Python first. I think OS X and most Linux distros already have it, but if they don’t, go to the previous link and get it.
Nicholas Kristof recently put up an article about Bing censoring simplified (mainland) Chinese searches. All of the major search players do this of course, but what’s new is that the censoring happens when if you’re searching from a U.S. IP address (as opposed to within China itself).
Kristof uses Tiananmen (天安门) as his search term, but I think that’s a little ambiguous. Tiananmen Square has a history that stretches well before 1989 (trivia of the day: the 1989 incident was not the first Tiananmen Square incident) and as a popular tourist location, it’s plausible that Bing’s algorithm would turn up lots of friendly-Tianamen-is-a-nice-place-to-visit results.
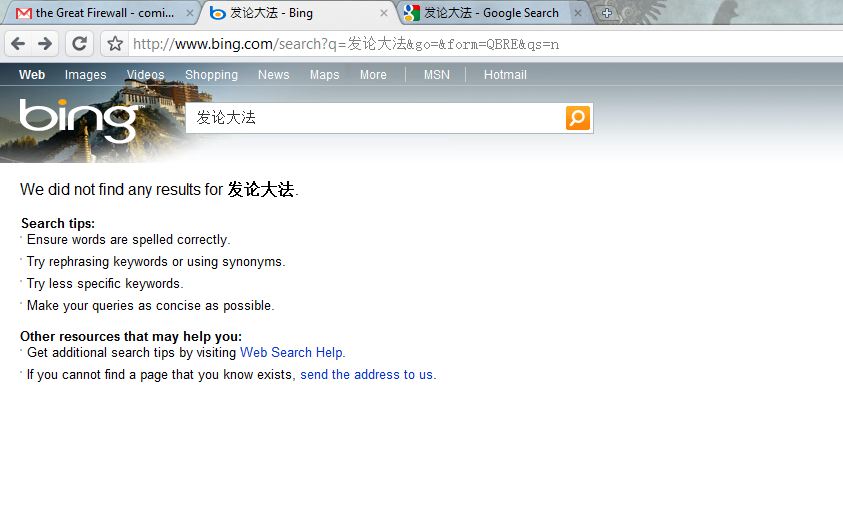
So let’s try the name of a certain evil cult outlawed in China.
For comparison, here’re the Google results:
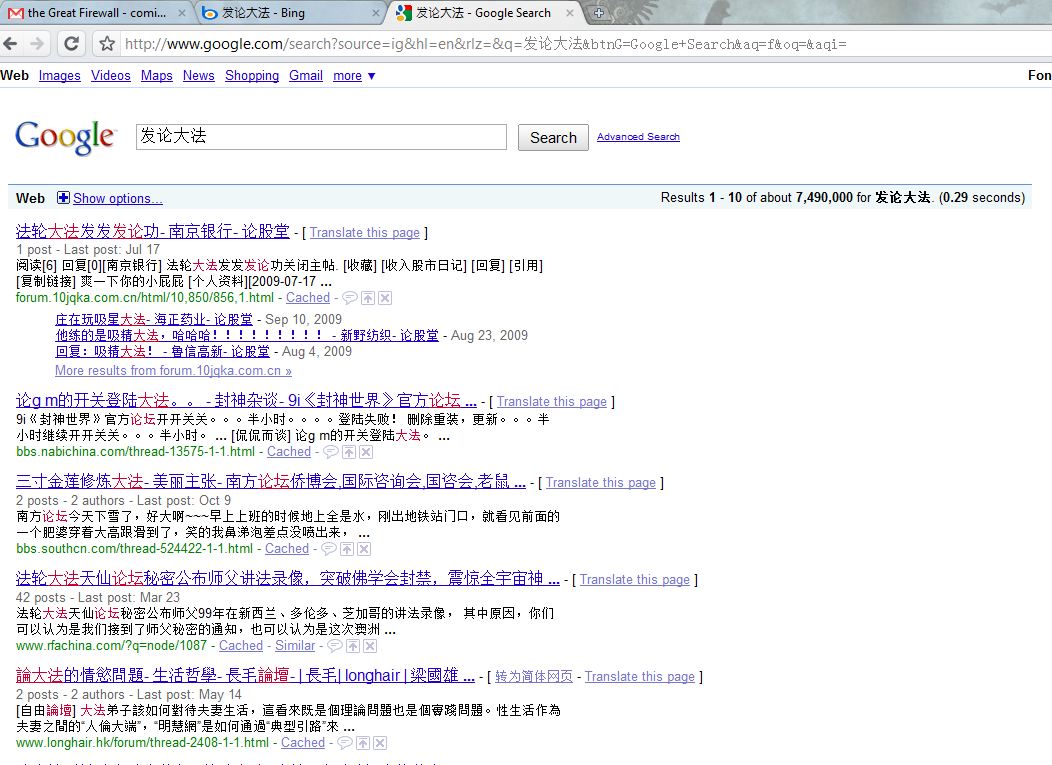
Google has 7,490,000 results and Bing has 0? Now that’s implausible.
Interesting notes:
- Today’s Bing background is of Potola Palace in Tibet, the former home of the Dalai Lama.
- Google includes traditional Chinese character results in search results using simplified Chinese characters (see the last item in the screenshot above).
One of my issues with copyrights and patents are setup is how arbitrary their length is. Copyrights lasts for your entire life + 70 years. A patent lasts for 20 years. That seems odd to me. The end result of billions of dollars worth of product development can be under protection for a shorter amount of time than some doodle you scribbled on a napkin one afternoon.
Ideally, the length of time a copyright or patent lasts should be tied to market behavior by producers. I’m not sure how’d you make this work, but as a starting point, the market value of a copyrights or patent should correspond roughly to your sunk costs in producing the relevant intellectual property. One you account for those, I feel the law shouldn’t offer any additional protection. You are of course, entitled to try to earn a profit, but your profits should come not from a monopoly but from making a better product than your competitors — and I mean competitors in a very narrow sense. For example, I’d like to choose between book publishers based on factors like the quality of the paper or which ones offer digital copies, as opposed to which one of them managed to snag the exclusive rights to a book first.
I really can’t justify sunk costs as a barometer of the ideal value of a copyright over say, sunk costs + 20%, but it seems to jive from from the standpoint of putting the original content producer on a level playing field with the copycats. If anyone has thoughts on this, I’d be interested in hearing them.
This happens pretty frequently in Berkeley. Buses on a given line are spaced 10 minutes apart. Bus A swings by a stop around 9:40AM. A large number of students with 10AM classes pile on. Because there are so many people getting on the bus, Bus A falls a little bit behind schedule. At 9:50, Bus B swings by the stop, which is now empty. B spends relative little time there and is now ahead of schedule.
The same thing happens at the next few stops. As more and more people hop on Bus A, it falls further and further behind schedule. As it falls further and further behind schedule, more and more people accumulate at stops ahead of Bus A. Feedback loop ensues.
Meanwhile, as Bus A is falling further behind schedule, Bus B is increasingly getting ahead of schedule. Since Bus A was late, the gap in time between Bus A and Bus B is now smaller than anticipated. That smaller gap in time means that fewer people have accumulated (i.e. people who normally ride Bus B now ride Bus A). Less people to pick up means less people to drop off means less time at any given stop. Bus B gets further ahead of schedule, narrowing the gap between it and Bus A. Another feedback loop.
Eventually, Bus B catches up to Bus A, and you get this very annoying scenario of a long wait-time followed by two back-to-back buses. Meanwhile, because B was so far ahead of schedule, the gap between it and Bus C starts to grow. Bus C starts taking on passengers that missed Bus B (because it came and left the stop earlier than the time listed) and starts to fall behind schedule. The cycle repeats.
There is a slight correction mechanism here. If the driver of Bus B is smart, she’ll drive ahead of Bus A and try to even out the load distribution by picking up those large masses of waiting passengers that otherwise would’ve hopped on Bus A. Still, it’s not ideal. The delays and unpredictability is frustrating as heck, but I’m not sure how’d you get around it. Thoughts?